TPU vs GPU 완전 정복: 2025 최신 비교 가이드
요즘 AI 모델을 다루다 보면 한 번쯤 이런 고민을 하게 됩니다. “GPU가 좋대서 샀는데, TPU가 더 빠르다던데?” 저 역시 처음엔 GPU만 알고 있었어요. 그런데 실제로 여러 모델을 학습시키고, 서로 다른 클라우드 환경에서 성능을 비교해보면서 “둘은 태생부터 목적이 다르구나”라는 걸 깨달았습니다. 이 글에서는 TPU와 GPU의 차이를 기술적 내용은 최대한 쉽게, 하지만 중요한 포인트는 놓치지 않도록 차근차근 풀어보려 합니다. 복잡한 용어 대신 체감되는 비유와 실제 사용 사례를 중심으로 설명해 드릴게요.

GPU와 TPU의 기본 개념
GPU는 원래 게임 그래픽을 처리하기 위해 만들어졌지만, 점점 병렬 계산 능력이 뛰어나다는 점이 알려지면서 딥러닝·과학 계산·영상 처리 등 다양한 분야에서 범용적으로 쓰이기 시작했습니다. 수천 개의 코어를 동시에 움직여 방대한 연산을 빠르게 처리하는 것이 강점이에요. 특히 NVIDIA의 CUDA 생태계는 개발자에게 거의 ‘표준’처럼 받아들여지고 있어서, 딥러닝을 해본 사람이라면 대부분 GPU 환경을 먼저 떠올립니다.
반면 TPU는 Google이 처음부터 인공지능을 위해 설계한 전용 장치입니다. 특히 행렬과 텐서 연산 속도를 극단적으로 끌어올리기 위해 설계되었어요. GPU가 다양한 일을 할 수 있는 만능 도구라면, TPU는 초대형 모델을 ‘훈련’하는 데 최적화된 전문 기계라고 볼 수 있습니다. Google 내부 서비스(예: PaLM, Gemini)는 모두 TPU Pod 환경에서 훈련되며, 2025년 기준 TPU v5e 제품군은 에너지 효율 측면에서도 매우 뛰어난 것으로 평가됩니다.
“TPU는 대규모 모델 학습에 최적화된 전용 아키텍처로, Google의 내부 LLM 학습에서 핵심 역할을 수행하고 있다.” — Google Cloud, 2024
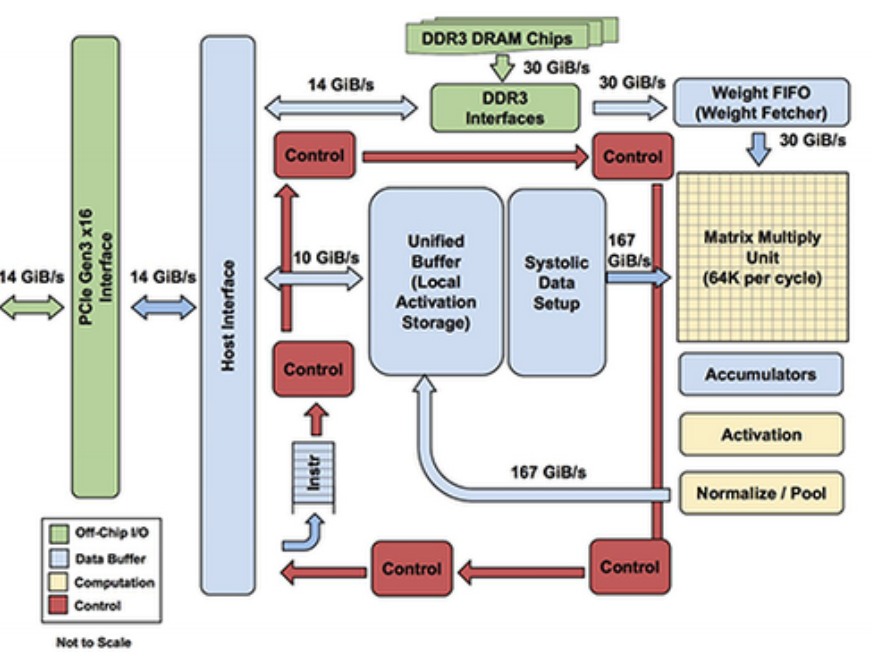

구조적 차이
GPU는 SM(Streaming Multiprocessor)이라는 작은 연산 집합 단위를 여러 개 묶어 구성된 구조입니다. SM 안에는 다양한 데이터 타입을 다루는 유닛, 캐시, 스케줄러 등 범용 계산을 위한 로직이 풍부하게 포함돼 있어요. 그래서 딥러닝뿐 아니라 그래픽, 영상 처리, 로보틱스, 시뮬레이션 등 여러 분야에서 균형 잡힌 성능을 보여줍니다.
반면 TPU는 MXU(Matrix Multiply Unit)라는 거대한 행렬 연산 장치를 중심으로 구성됩니다. 쉽게 말하면 “행렬 곱셈을 가능한 한 빠르게 처리하는 머신”에 가까워요. 복잡한 그래픽 처리 기능을 거의 배제하고 행렬 연산을 위한 구조에 집중해 전력 효율을 크게 높였고, 반복적인 GEMM 연산에서 GPU보다 훨씬 높은 성능을 낼 수 있습니다.
성능 비교 (2025 기준)
성능을 비교할 때 많은 분들이 “GPU가 빠르다던데?”, “TPU가 더 좋다던데?”처럼 단순 비교를 하려고 합니다. 하지만 두 장비는 애초에 목적이 다릅니다. GPU는 범용적이라 추론·학습 모두에서 안정적인 성능을 보이는 반면, TPU는 초대형 모델을 훈련하는 상황에 최적화되어 있어요. 예를 들어 TPU v4/v5 Pod는 ExaFLOPS 단위까지 확장되기 때문에 수백억~수천억 개 파라미터를 가진 모델 학습에서 강력한 성능을 보여줍니다.
- ✔ GPU: 추론 성능이 매우 뛰어나고 최적화 도구(CUDA, TensorRT)가 빠르게 진화
- ✔ TPU: 초대형 LLM 학습에서 전력 효율 대비 성능이 탁월
- ✔ TPU v5e는 학습 에너지 비용을 크게 절감하는 것이 목표
실제 사용 환경 차이
실제 현업에서는 “어느 쪽이 더 빠르냐”보다 “어디에서, 어떤 워크로드에 쓰느냐”가 더 중요합니다. GPU는 로컬 워크스테이션, 온프레미스 서버, 여러 퍼블릭 클라우드까지 선택지가 매우 넓습니다. 중소 규모 팀이 사무실 한 켠에 GPU 서버 한 대를 들여놓고, PyTorch 기반으로 실험·프로토타입·서비스 추론까지 한 번에 해결하는 패턴이 여전히 가장 흔해요. 클라우드에서도 AWS, Azure, GCP 모두 다양한 GPU 인스턴스를 제공하기 때문에 인프라 선택의 자유도가 높습니다.
반면 TPU는 Google Cloud에 종속된 형태로 제공됩니다. 즉, 온프레미스나 다른 클라우드로 가져오는 선택지는 없고, GCP 환경에서만 사용할 수 있다는 의미입니다. 대신 Google은 TPU Pod를 기반으로 한 초대형 학습 클러스터를 제공해, PaLM·Gemini 같은 거대 모델을 짧은 시간 안에 반복 학습할 수 있도록 돕고 있습니다. TensorFlow·JAX와의 통합이 깊기 때문에, 해당 스택에 익숙한 팀이라면 인프라 설계 고민 없이 “바로 대형 모델 학습”에 집중하기 좋습니다.
한마디로 정리하면, GPU는 “어디서나 돌아가는 기본 선택지”이고, TPU는 “Google Cloud 안에서 초대형 학습을 밀어붙일 때 쓰는 특수 옵션”에 가깝습니다. 이 차이가 실제 프로젝트의 비용 구조, 운영 방식, 인력 구성까지 영향을 주게 됩니다.
어떤 상황에서 어떤 장비가 더 유리한가?
이제 “우리 팀은 무엇을 써야 할까?”라는 실질적인 질문으로 들어가 보겠습니다. 팀 규모, 예산, 사용하는 프레임워크, 목표가 되는 워크로드(연구·서비스·실험용 등)에 따라 정답이 달라집니다. 아래 표는 흔히 등장하는 몇 가지 상황을 정리한 것입니다. 실제로는 비용 견적, 기존 기술 스택, 인력 경험까지 함께 고려해야 하지만, 방향을 잡는 데에는 충분히 도움이 될 거예요.
정리하면, “어디서든 쉽게 쓰고 싶다, 프레임워크도 제약 없이 쓰고 싶다”면 GPU가 훨씬 편합니다. 반대로 “우리는 이미 GCP·JAX에 익숙하고, 초대형 모델 학습 속도가 최우선이다”라면 TPU가 좋은 선택이 될 수 있습니다. 특히 학습 비용을 시간 단축 관점에서 본다면, 일정 규모 이상에서는 TPU Pod가 더 경제적인 경우도 생깁니다.
TPU vs GPU 한 줄 요약
마지막으로, 지금까지의 내용을 실제 선택에 바로 써먹을 수 있도록 리스트로 정리해 보겠습니다. 복잡한 스펙을 모두 외울 필요는 없고, 아래 몇 가지만 기억해 두면 새로 하드웨어를 도입할 때나 클라우드 옵션을 고를 때 훨씬 수월해질 거예요.
- ✅ GPU = 범용성 + 생태계 + 추론 친화 — 어디서나 쓰이고, PyTorch·CUDA 기반 개발에 최적
- ✅ TPU = 초대형 딥러닝 학습 특화 — Google Cloud, TensorFlow·JAX 환경에서 진가 발휘
- ✅ 서비스 운영·추론·멀티미디어 작업까지 고려한다면 기본 선택지는 대부분 GPU
- ✅ 연구용 초대형 LLM을 반복적으로 학습해야 한다면 TPU Pod를 진지하게 검토할 가치가 큼
- ✅ 최종 선택 키워드: “우리 팀이 이미 쓰고 있는 프레임워크, 클라우드, 예산 구조는 무엇인가?”
한 줄로 요약하면, GPU는 어디에나 어울리는 만능 도구이고, TPU는 거대한 AI 모델 학습을 위한 특수 장비입니다. 이 두 가지 이미지만 머릿속에 선명하게 그려두면, 새로운 하드웨어 뉴스나 클라우드 옵션을 볼 때도 훨씬 빠르게 이해하게 되실 거예요.
Q&A
마치며
GPU와 TPU 중 무엇을 선택해야 할지 고민하는 분들이 정말 많습니다. 저 역시 처음에는 “둘 다 빠르다는데 뭐가 다른 거지?”라는 생각으로 시작했어요. 그런데 실제 모델을 학습시키고 인프라를 구축해보니, 둘은 태생적인 목적부터 완전히 다르다는 걸 알게 되었죠. GPU는 로컬에서도, 클라우드에서도, 연구·추론·서비스까지 어디에나 잘 맞는 만능 도구입니다. 반면 TPU는 초대형 모델을 훈련하는 데 초점을 맞춘 특수 장비로, Google Cloud라는 환경에서 진짜 힘을 발휘해요.
결국 선택은 팀과 프로젝트의 상황에 따라 달라집니다. “우리는 PyTorch 기반으로 개발하고 있고, 서비스 추론도 필요하다면” GPU가 가장 현명한 선택입니다. 반대로 “우리는 JAX·TensorFlow 중심이고, LLM을 반복해서 대규모로 학습해야 한다면” TPU가 시간·비용 면에서 큰 이점을 가져다줄 수 있어요. 본문에서 정리한 기준만 기억해두면 앞으로 새로운 모델을 실험하거나 인프라를 확장할 때 훨씬 더 정확한 판단을 내릴 수 있을 거예요.
앞으로도 AI 모델 규모는 계속 커지고, 학습 비용과 속도는 개발 경쟁력의 핵심 요소가 될 겁니다. 이번 글이 여러분의 선택을 조금이라도 더 명확하게 해주는 나침반이 되었기를 바랍니다. 혹시 TPU나 GPU 환경 구축에 대해 더 궁금한 점이 있다면 Q&A 섹션을 다시 참고하시거나, 댓글로 의견을 알려주세요. 여러분의 경험이 또 다른 누군가에게 큰 도움이 될 수 있으니까요.
태그: TPU, GPU, 딥러닝, LLM학습, AI가속기, GoogleCloud, NVIDIA, TensorFlow, JAX, PyTorch

'경제, AI 소식' 카테고리의 다른 글
| 2025 분당 선도지구 특별정비구역·토지정비구역 설정 (0) | 2025.12.04 |
|---|---|
| 쿠팡 3370만건 정보 유출 사태 (0) | 2025.11.30 |
| 서울 휘발유 1800원 돌파, 왜 이렇게까지 올랐을까? (0) | 2025.11.22 |
| 1500원 초읽기, 원달러 환율 급등이 의미하는 ‘진짜 변화’ (0) | 2025.11.09 |
| 테슬라를 뚫은 삼성SDI, 3조 ESS 배터리의 의미 (0) | 2025.11.08 |



